(事例・応用例)
こんにちは。
Part 1では「強化学習の概要」を紹介し、Part 2では「ボールの自動転がし」について、シミュレーション上で行った様子を紹介しました。
いよいよ今回のPart 3では、実際の機材を使用して、強化学習を用いたボールコントロールを行ってみたいと思います。
前回のおさらいとなりますが、図1は「ボールの自動転がし」に使用する実際の機材構成です。カメラでボールの位置を捕捉し、ステージの下にある高さセンサーで、ステージの状態をとらえています。
2個のサーボモータを回転させてステージを上下させることにより、ボールを「円」や「8の字」に転がそうとしています。仮想の(見えない)ネズミをボールが追いかけるように(強化学習で)学習を行っています。
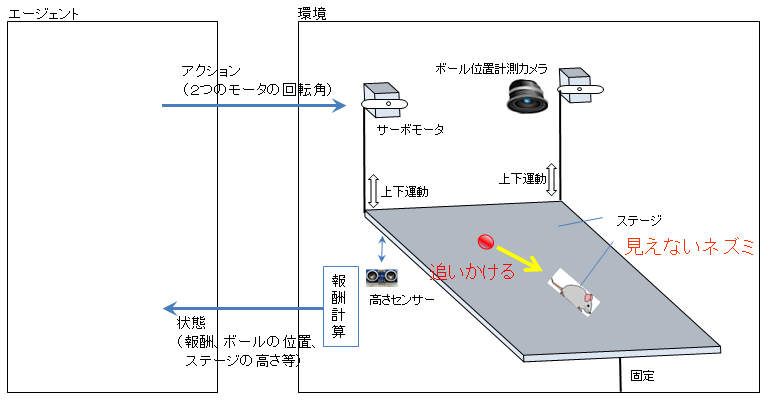
図1 ボール転がし機の全体像
1 実機を使用した再学習(Fine-tuning)
コンピュータで使用する強化学習のモデルは、前回 Part 2 の「シミュレータを使用して学習したモデル」を使用します。このモデルは仮想の(見えない)ネズミをボールが追いかけるように学習していますが、実際の機材とシミュレータではボールの動きが若干異なることや、実機ではリアルタイム通信処理等での時間のズレが発生してしまうため、「シミュレータを使用して学習したモデル」をそのまま実機に適用しても、ボールの動きが不安定になるときがあります。
そこで、「シミュレータを使用して学習したモデル」をベースに、実機を用いて少しだけ再学習(Fine-tuning)しています。これにより、ボールの動きが安定します。
2 ネズミを追いかけるボール
強化学習では、仮想の(見えない)ネズミをボールが追いかけるように学習しています。ここではプレゼンテーション用のレーザーポインター(緑色)を手に持って、ステージに照射します。照射された「緑色の点」をネズミとみて、その点をボールに追わせてみます。
うまく学習ができていれば、レーザーポインタの光をボールが追いかけるように、2個のサーボモータが動きます。
(「緑色の点」の位置は、ボール位置計測用カメラで補足します)
図2は実機での実行結果です。レーザーポインターの緑の点をボールがうまく追っています。
ここでは、レーザーポインターで文字「ね」を書いてみました。ねずみの「ね」です。
ステージ上のボールも「ね」を描いているようにみえるでしょうか?
図2 ネズミを追いかけるボール
(ステージの隅にあるボールは、WEBカメラの位置ずれを補正するためのボールです。)
3 ボールを円状に転がす
次に、ボールを円状に転がしてみます。これは、上記の「2 ネズミを追いかけるボール」の応用です。
反時計回りに円状に逃げる仮想のネズミを作り出し、それをボールに追わせています。(ステージ上にネズミはでてきません)
図3は実機での実行結果です。ボールがうまく円を描いています。
図3 円状に転がるボール
4 ボールを8の字に転がす
次に、(見えない)ネズミがステージの上を8の字に逃げるパターンを行います。仮想の(見えない)ネズミが8の字に動くため、それを追うボールも8の字に動きます。
図4は実機での実行結果です。ボールが8の字を描いています。
図4 8の字に転がるボール
5 ボールを静止させる
システム制御工学の基本、「静止」 を行ってみます。
(見えない仮想の)ネズミがステージの上で寝転んで止まっている状態です。ネズミが止まれば、(ネズミを追いかける)ボールも止まるはずです。
図5は実機での実行結果です。動いていたボールがステージの中央付近で、ピタッと静止します。
図5 ボールを静止させる
6 サーボモータが故障したら? -環境変化への柔軟な対応
最後に、ボール転がし機のサーボモータが故障した状況を考えてみたいと思います。
この故障は人為的に作りだします。(ボールが円を描いている)ある瞬間から、片方のサーボモータの一回の制御で動ける角度が半分になり、片方のサーボモータの動きが鈍くなるという状況を作り出します。
図6は、片方のサーボモータの動きが鈍くなったため、それまで丸く円を描いていたボールが、円を描くことができず、乱れてきた状況を示しています。
このような状況でも、強化学習は自律的な学習をすすめることができるので、「片方のサーボモータが壊れた状況が現在の正しい環境」としてとらえて学習をすすめ、しばらくすると再びボールが丸く円を描くようになります(図7)。これは上記1で述べた「再学習」と同じ要領です。
強化学習は高度な制御を可能にする道具であると同時に、このように自律的な学習を行うことができる点も強化学習の大きなポイントだと思います。システムの経年劣化への自動対応や、「均一機能であるはずの製品」の最後の仕上げ(tuning)などにも利用できそうです。
図6 サーボモータ故障時のボールの動き (故障発生時)
図7 自動復旧(再びボールが円を描く)
「ネズミを追いかけるボール」シリーズは今回が最終回です。当初、「ネズミを追いかけるボール」を考え始めた頃は、パソコンのマウス(ネズミ)を画面上に映して、動き回るパソコンのマウスをボールに追わせることを考えていました。しかしこれは最終的にレーザーポインターをボールが追いかける形にしたため、せっかくのネズミの「落ち」が消えてしまった感があります。
強化学習は機械学習の中の一分野で、以前から研究が進められていたようですが、その機械学習がディープラーニングと出会ったことにより、システム制御工学の分野でも、今後さらに活躍することになろうとは数年前には考えられませんでした。これも「AlphaGo」のおかげですね。
強化学習は車の自動運転技術などにも取り入れられているとのことですが、センサーを用いた様々な制御システムにも、今後活躍の場を広げていくように思います。
もっと楽ができる時代が、すぐそこまで来ているということですね。