(事例・応用例)
こんにちは。
前回のPart 1では強化学習の概要についてお話をしました。今回は強化学習の事例を紹介したいと思います。
~関連ブログ~
「強化学習でボールを自由に動かす ~ネズミを追いかけるボール~ Part 3 実際の機材を使用した強化学習(事例・応用例)」
1 ボールの自動転がし
ここで紹介する事例は、 「ボールの自動転がし」です(図1)。
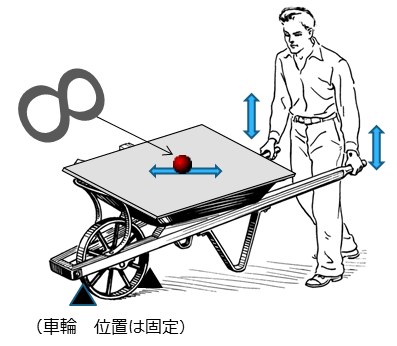
図1 工事用一輪車(手押し車)
図1のように、工事用の一輪車に平らな板を載せ、その板の上にボールを置きます。この一輪車を左右の手で上下させることにより、板の上のボールを自由自在に転がそうというものです。ボールを板の上でピタッと静止させたり、「8の字」の形にボールを転がしたいと考えています。
ここでは本物の一輪車は使いません。図2のような機材を用います。人の眼をカメラに、人の手をサーボモータに置き換えて、ステージの上のボールを自動的に、自在にコントロールすることを目標にしています。
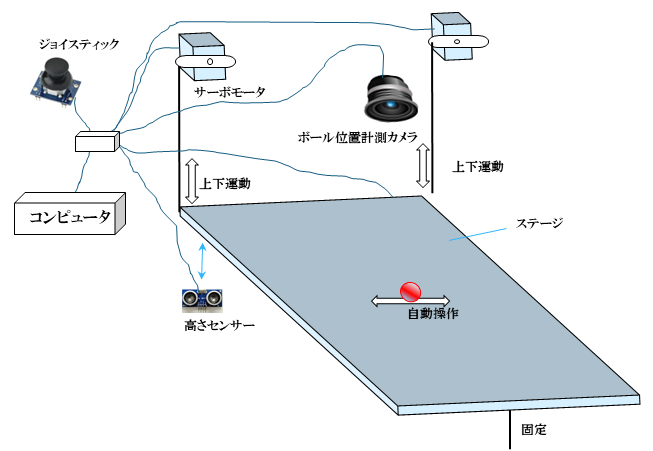
図2 ボール転がし機
このような技術はシステム制御工学の「フィードバック制御」と呼ばれる中の一つのようですが、ここでは強化学習を用いてボールのコントロールを行います。
カメラは通販で購入したパソコン用のWEBカメラ、サーボモータは秋葉原で購入したホビー用のサーボモータです。ボールにはビー玉を使用しています。
2 全体像
強化学習の全体像は図3のとおりです。エージェントから環境へサーボモータの回転角を伝えます。サーボモータが回転することによりステージが上下に動き、ボールがステージ上を転がります。
(見えない仮想の)ネズミをボールがうまく追いかけるように学習することを目標とします。ネズミは自由に(ランダムに)ステージ上を逃げますが、ボールがネズミに近づいたら高い報酬を、ネズミから離れたら低い報酬を与えます。
学習がうまくすすめば、
①仮想のネズミが静止すると、ボールも静止する
②仮想のネズミが「8の字」に逃げ回ると、ステージ上でボールが8の字を描く
ようになります。
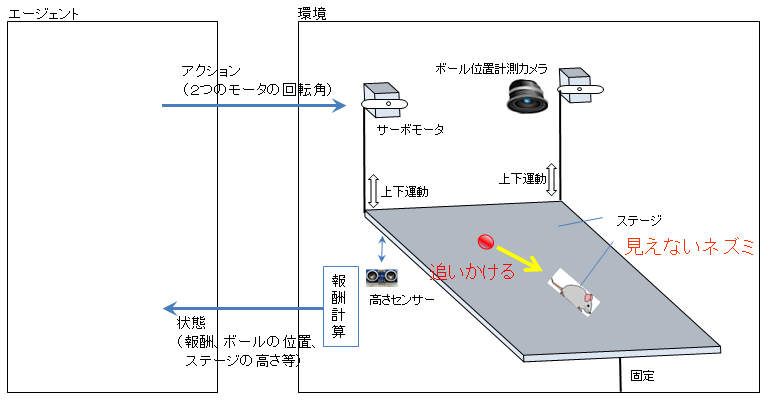
図3 全体像
強化学習は、様々なアクションをエージェントから環境に与え、環境から戻される報酬の値をみながら、良いアクション、悪いアクションをエージェントが学んでいきます。エージェントは、アクションを数十万回、数百万回繰り返しながら、高い報酬をもらえる最善のアクションを学んでいくことになります。
しかしながら、ここで一つ問題がでてきます。図2の「ボール転がし機」は、はたして数十万回、数百万回の動作に耐えられるでしょうか?もし耐えられたとしても、数百万回の繰り返しにはどのくらいの時間がかかるのでしょうか?
仮に0.1秒間隔でエージェントがアクションの指示を環境に伝えた場合、500万回繰り返すには約6 日もかかってしまいます。
0.1秒 × 5,000,000 回 = 500,000秒 = 139 時間 = 5.8 日
その間、このサーボモータから火がでないか、ステージがバラバラにならないか、常に人が寝ずの番をすることになります。実機を使って直接強化学習を行うのは、忍耐と大きなコストがかかってしまいます。仮に6日間頑張って学習を終えたとしても、それが想定通りの良い結果になるとは限りません。結果が悪い場合は少しパラメータを変えて、また6日間頑張ることになります。こうなるともう、試練といいますか、強化学習は心と体の強い人だけが生き残って利用するという道具になってしまいます。
これを解決するためには次の二つの方法がありそうです。
①実機を複数台使用する
なによりその6台分のスペースがないのと、サーボモータの音があまりにもうるさくて、周りに迷惑がかかりそうだからです。
②シミュレータを使用する
今回はこのシミュレータ方式を採用しました。こちらであれば、ほぼ無音です。
今回は対象を「ボール転がし機」としていますが、対象が「自動車」のような場合、実際の自動車を動かしての学習は、大きなコストともに、車の暴走という危険も伴いますので、実機を使って最初から強化学習を行うことは難しい状況のようです。
3 シミュレータの作成
ステージを「平らな坂」とみれば、このボール転がしでは、「坂を転がる球体の物理法則」が適用できそうです。しかしながら、「ボール転がし機」ではステージが上下するため、サーボモータ近くでは上下方向に加速度が発生します。また、ステージ自体の歪みや、ステージ上でのボールの転がり抵抗などを考えると、「坂を転がる球体の物理法則」をそのまま当てはめることは難しいようです。
そこで、「ボール転がし機」のセンサーからでる情報をログとして保存し、ディープラーニングを使用して、ログデータをもとに「ボール転がし機」を模倣するようなシミュレータを作成しました。「ボール転がし機」のセンサーからでる情報をもとにシミュレータ自体を作成するため、実機の特性を反映したシミュレータを作成することができると考えました。
図4は、作成したシミュレータの出来栄えをみるために、シミュレータを使ったボールの動きをコンピュータ画面上で確認したときの動画です。サーボモータ側のステージを下げた状態にした時のボールの動きを表示しています。
ボールがサーボモータ側へ転がり、ステージの壁にぶつかって跳ね返っている状況をうまく再現しています。どうやらシミュレータは上手にできあがっているようです。
図4 作成したシミュレータの動作例
4 強化学習による学習
シミュレータが出来上がりましたので、このシミュレータを使用して強化学習(の学習)を始めます。仮想のネズミをボールがうまく追いかけるように学習することを目標とします。
図5はシミュレータを用いた場合の学習方法です。実時間での計算ではないため、実機を用いた学習に比べ、はるかに短い時間で、そして静かに学習を進めることができます。
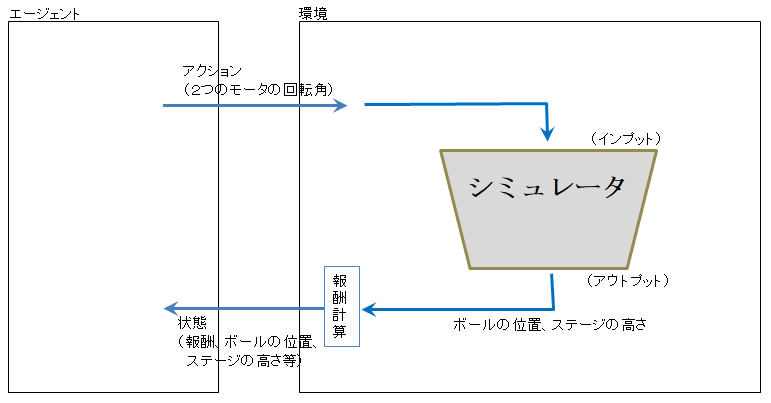
図5 シミュレータを用いた強化学習
図6はシミュレータを用いて行った強化学習の結果です。黒い玉がネズミです。逃げ回る仮想のネズミをボールがうまく追いかけているように見えます。
(ボールがネズミを追いかけるよう)エージェントから「サーボモータのアクション指示」が環境に伝えられ、ステージが上下することにより、(現実世界の重力ではなく)シミュレータがボールを動かしている、という状況になります。
この仮想のネズミが円上に逃げれば、ボールは円を描くように動き、仮想のネズミが「8の字」に逃げれば、ボールは「8の字」を描くように移動するということになります。
図6 仮想のネズミを追いかけるボール
図6のように、シミュレータを用いた強化学習がうまくいったとしても、現実世界の実機がうまく動作するとは限りません。仮にシミュレータが間違った結果を出力していても、間違っていたなりに強化学習がそれを覚えてしまうためです。
例えば、作成したシミュレータのボールの加速度が現実世界の1,000倍にもなったとしても、それを正しいものとして、強化学習は学習を進めてしまいます。このような場合、エージェントからのアクションをそのまま実機に適用しても、実機はまったく動きません。シミュレータの推測精度が非常に大きなポイントになるということになります。
さて、次回はいよいよ実機を使用してボールを上手にコントロールすることに挑戦したいと思います。