こんにちは。
今回は、最近世間で注目されている ビッグデータ の取り扱い方について考えてみたいと思います。
ビッグデータとは
ビッグデータは以下のように定義されています。(もっと詳しく知りたい方は こちら をご覧ください)
市販されているデータベース管理ツールや従来のデータ処理アプリケーションで処理することが困難なほど巨大で複雑な データ集合の集積物を表す用語である。
「巨大」というのが1エクサバイトなのか1ペタバイトなのかは意見が分かれる所ですが、つまりは「今までのやり方じゃ処理出来ないくらい大きなデータの集まり」と言えるでしょう。
今までは、処理しきれないから捨ててしまっていた巨大なデータを、もう一度見直して利益につなげていこうじゃないか!!という動きが活発になったので、ビッグデータが注目されています。それは「大手ECサイトの全アクセスログ」であったり、「日本全国の高速道路交通量」であったりと実に多種多様。
そんなビッグデータを取り扱うための仕組みとして、一番認知されているのが今回取り上げます「Hadoop」です。
Hadoopとは
Hadoopは、「大規模分散計算フレームワーク」と呼ばれています。
特徴としては、分散ファイルシステム(HDFS)と並列処理フレームワーク(MapReduce)があります。
それだけ聞いてもよくわからないですよね…。なので、誤解を恐れず簡単に説明します。
- 分散ファイルシステム (HDFS) とは…
たくさんの子サーバーにファイルを分散して配置。その時、子サーバーがいくつか壊れてもいいように、コピーしておく。
コピーしていろんな子サーバーに配置しておけば、 データを取得する時も、アクセスが集中せず便利!!
- 並列処理フレームワーク (MapReducd) とは…
たくさんの子サーバーに処理を分割して渡して実行してもらう。最適な処理を行うために、データの配置やサーバーリソースの管理もマスターサーバがきっちり行う。
分割した処理の中で、返ってこない処理があったら、即他のサーバーで再起動。HDFSと一緒に使えば使用するデータも並列取得できるのでさらに効率アップ!!
こんな感じで考えていただいて問題ないと思います。
Hadoopを使ってビッグデータの集計
それではHadoopを使用するとどれくらいのビッグデータが扱えるのでしょうか。
今回は100万店舗がランダムに1000万件の売上データを送信してきた場合を例に考えていきます。
Hadoopの集計方法 Hive, Pig と、MySQLサーバーではSQLを利用して集計します。各ツールの詳細等は以下のリンク先をご参照ください。
Hadoopのダウンロード・インストール等は こちら
Hiveのダウンロード・インストール等は こちら
Pigのダウンロード・インストール等は こちら
テスト環境
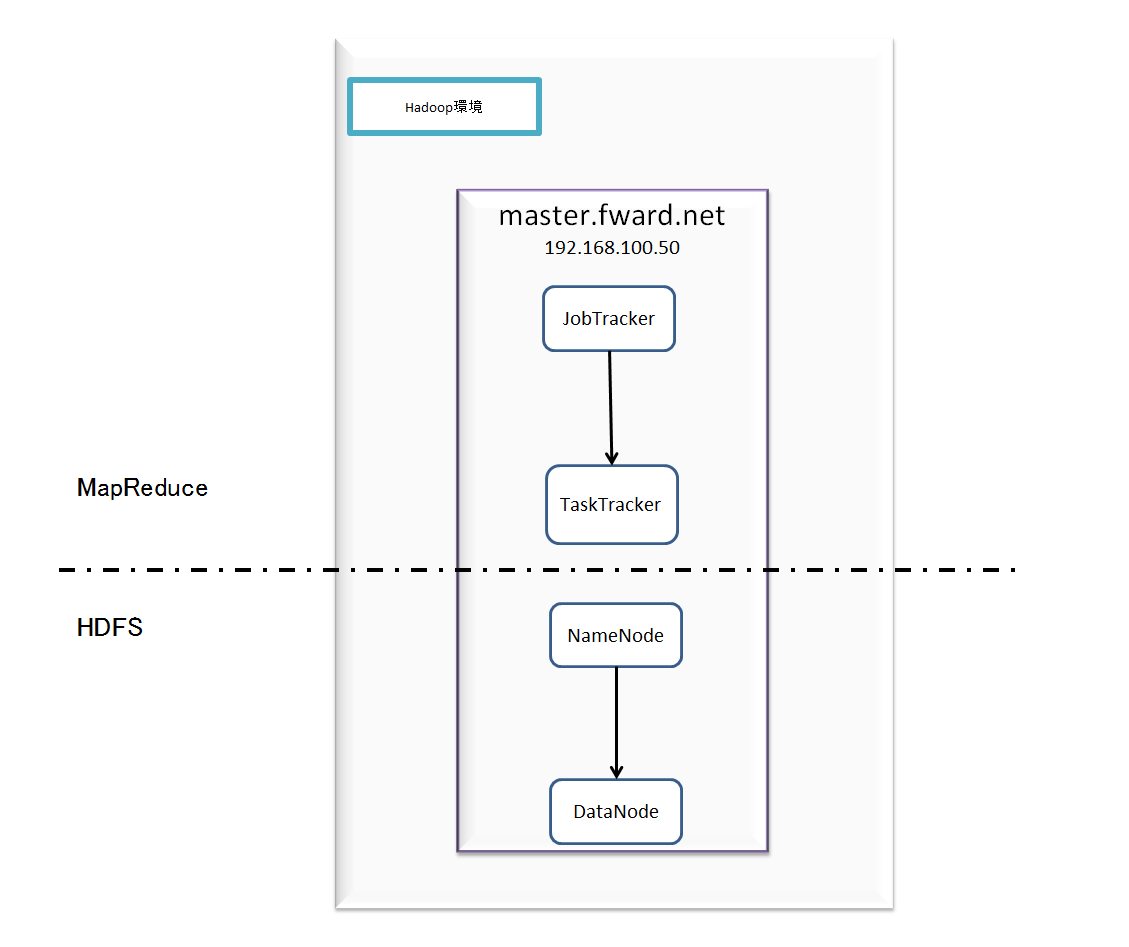
- 疑似分散環境
Hadoopの環境を疑似的に作成しました。1台のサーバー内にマスタとスレーブの両方が入っています。
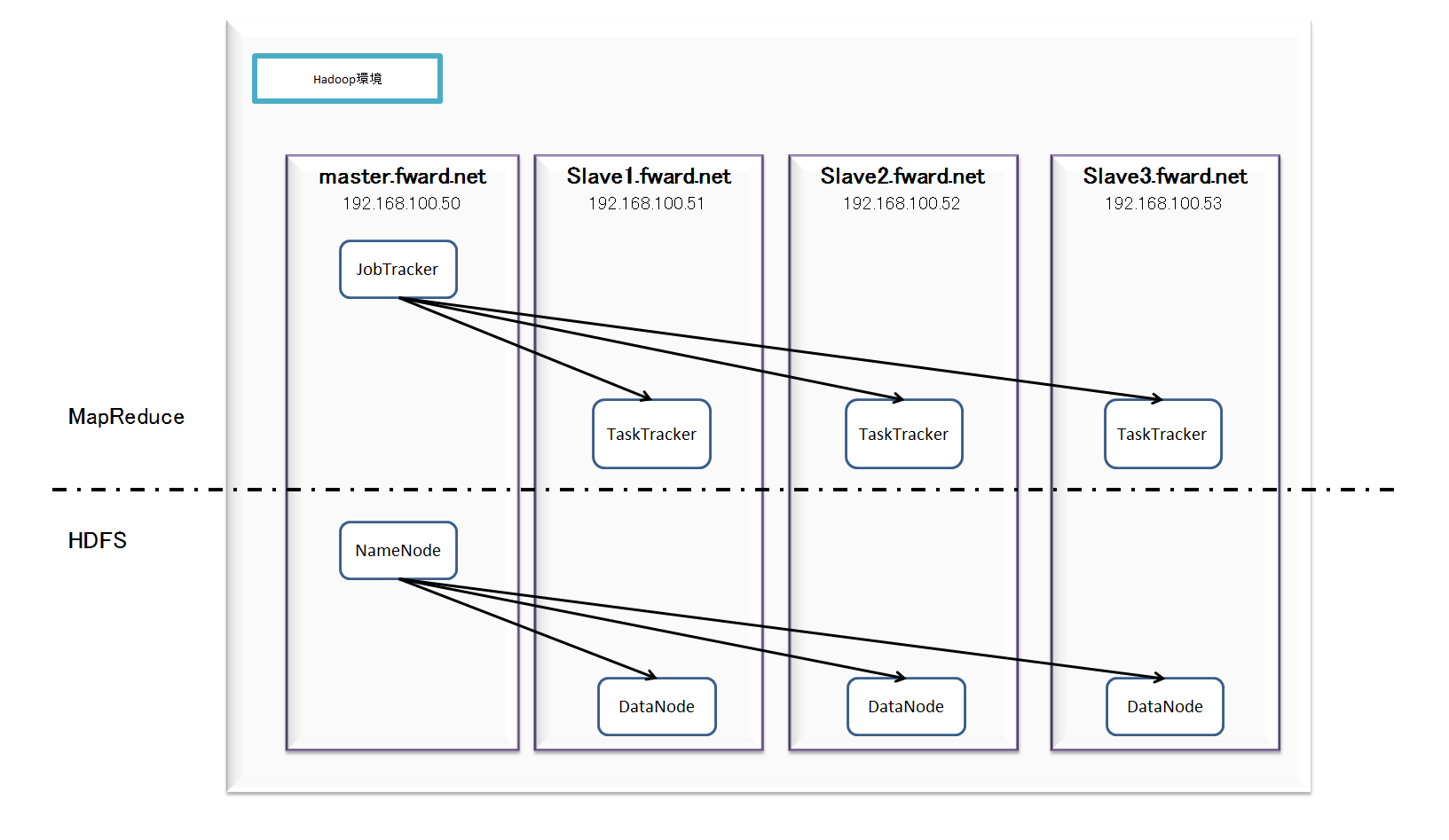
- 完全分散環境
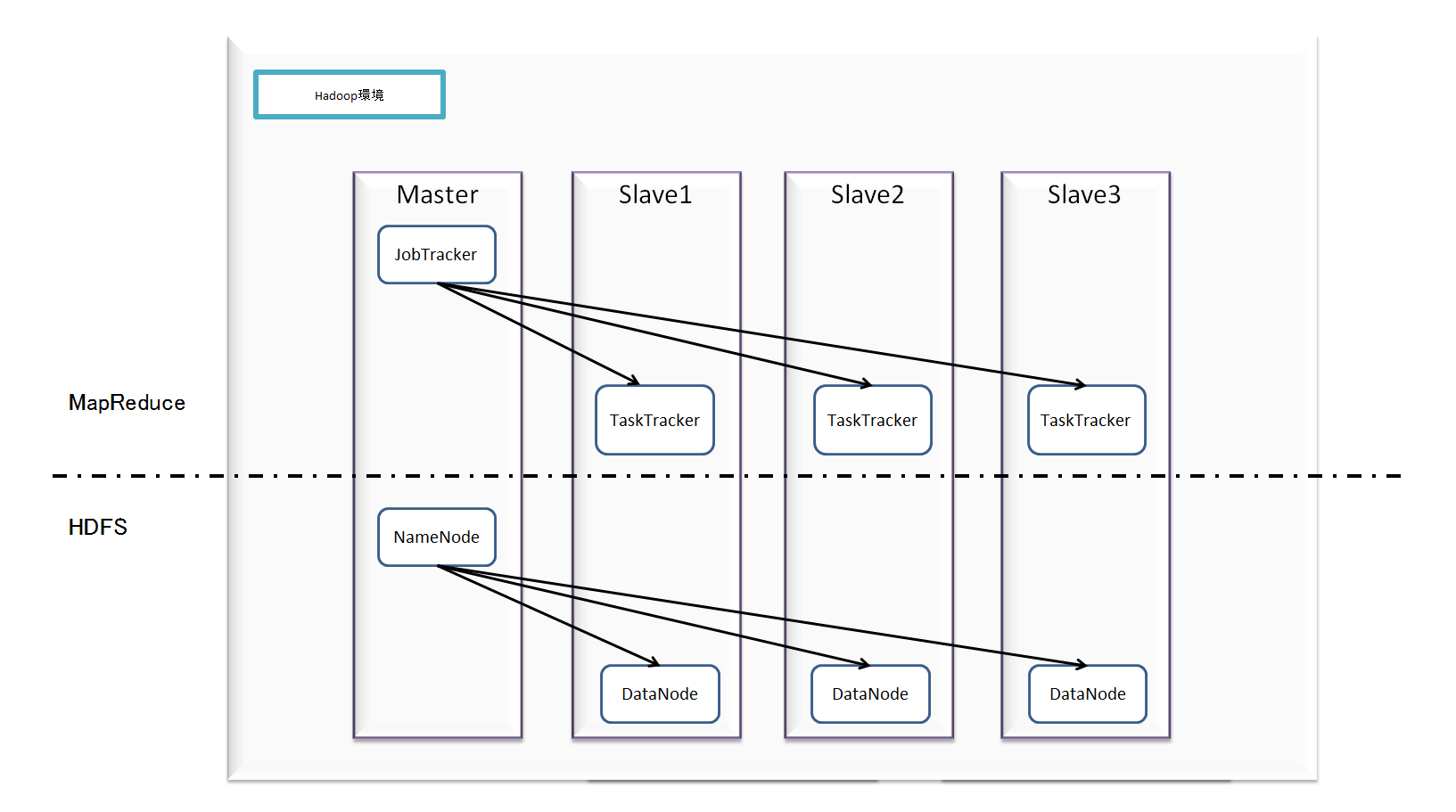
規模は小さいですが、完全分散型のHadoop環境です。マスタ1台とスレーブ3台で構成されています。
- 普通のRDBMS (mysql)
ごく普通のMySQL環境です。

テストデータ
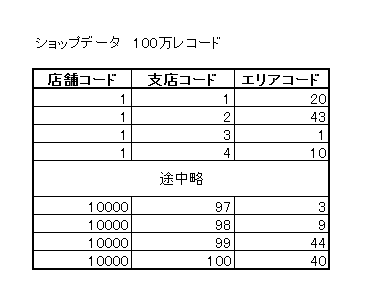
ショップデータ100万レコード、売上データ1000万レコードを使用します。
データの内容は以下の通りです。
集計方法・結果
売上データを店舗のエリア毎に集計します。
1. Hadoop – Hive
まずテーブルを作成し、HDFS上に置いたデータを読み込みます。
売上テーブル作成
CREATE TABLE sale_a ( id STRING, shopCode STRING, branchCode STRING, productCode STRING, price INT, num INT, amount INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE ;
売上テーブル読み込み
LOAD DATA INPATH '/hiveSample/bigData.log' into table sale_a;
ショップテーブル作成
CREATE TABLE shop_m ( shopCode STRING, branchCode STRING, areaCode STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE ;
ショップテーブル読み込み
LOAD DATA INPATH '/hiveSample/shopBranchMaster.log' into table shop_m;
データが揃ったので、以下のコマンドを実行し集計処理を行います。
select shop_m.areacode, sum(sale_a.price) as total from sale_a join shop_m on (sale_a.shopcode = shop_m.shopcode and shop_m.branchcode = sale_a.branchcode) group by shop_m.areacode;
最終的にHiveを使ってデータの格納・集計に掛かった時間は以下の通りです。
- 疑似分散環境 – 190秒
- 完全分散環境 – 170秒
2. Hadoop – Pig
PigはHiveと違い、データを格納するテーブルを作成する必要はありません。
そのため、データをHDFS上に用意したら、すぐにPigのコマンドで集計が行えます。
shopDatas = LOAD '/pigSample/shopData/shopBranchMaster.log'
USING PigStorage(',') AS (
shopcode:chararray,
branchcode:chararray,
areacode:chararray);
saleDatas = LOAD '/pigSample/saleData'
USING PigStorage(',') AS (
id:chararray,
shopcode:chararray,
branchcode:chararray,
productcode:chararray,
price:int,
num:int,
amount:int);
D = JOIN shopDatas BY (shopcode, branchcode), saleDatas BY (shopcode, branchcode);
DG = GROUP D by areacode;
E = FOREACH DG GENERATE group, SUM(D.amount) ;
dump E;
最終的にPigを使ってデータの格納・集計に掛かった時間は以下の通りです。
- 疑似分散環境 – 460秒
- 完全分散環境 – 340秒
3. MySQL – SQL
最後にMySQLを利用して売上集計してみます。
全てSQL文のみで実装していきます。
売上テーブル作成
create table sale_a ( id varchar(20) NOT NULL, shopCode varchar(50) NOT NULL, branchCode varchar(50) NOT NULL, productCode varchar(50) NOT NULL, price INT NOT NULL, num INT NOT NULL, amount INT NOT NULL, PRIMARY KEY (id) ) default charset utf8 collate utf8_unicode_ci;
売上テーブル読み込み
LOAD DATA LOCAL INFILE '/home/sqluser/dataInsert/bigData.log' INTO TABLE sale_a FIELDS TERMINATED BY ',';
ショップテーブル作成
create table shop_m ( shopCode varchar(50) NOT NULL, branchCode varchar(50) NOT NULL, areaCode varchar(50) NOT NULL, PRIMARY KEY (shopCode, branchCode) ) default charset utf8 collate utf8_unicode_ci;
ショップテーブル読み込み
LOAD DATA LOCAL INFILE '/home/sqluser/dataInsert/shopBranchMaster.log' INTO TABLE shop_m FIELDS TERMINATED BY ',';
データが揃ったので、以下のSQLを実行し集計処理を行います。
select shop_m.areacode, sum(sale_a.price) as total from sale_a join shop_m on (sale_a.shopcode = shop_m.shopcode and shop_m.branchcode = sale_a.branchcode) group by shop_m.areacode;
最終的にMySQLを使ってデータの格納・集計に掛かった時間は以下の通りです。
- MySQL環境 – 48時間程度待ってみても結果が戻ってこない
まとめ
今回は比較的小さなビッグデータ (1000万件 × 100万件) を使用して集計を行いましたが、MySQLだと集計結果を出せないような処理となってしまいました。同じようなスペックのサーバーを使用したHadoop環境では問題なく集計結果を得ることができたので、ビッグデータを扱うにはHadoopがかなり有用であると言えるでしょう。
スレーブサーバーの台数が少ないため、疑似分散環境と完全分散環境ではあまり結果に差は出ませんでしたが、スレーブサーバーを増やせば増やすほど、処理に要する時間は少なくなると考えられます。