こんにちは。
今回は「強化学習」についてお話をしたいと思います。
~関連ブログ~
「強化学習でボールを自由に動かす ~ネズミを追いかけるボール Part 1~ (深層学習 Deep Reinforcement Learning )」
人間は学習することによって、行動をより良いものに変えていくことができますよね。
コンピュータも自己学習をすることにより、より良い行動を取るようにすることができます。
それが強化学習です。
「強化学習で○×ゲーム(三目並べ)」の詳しい内容が書籍として出版されました。
詳しくはこちらをご覧下さい。
最近有名なのが、GoogleのDQN(Deep Q Network) でしょう。
シンプルなテレビゲームであるピンポンゲームを学習し、次第に強くなっていきます。
最初はほぼ負けているプレイヤー(コンピュータ)ですが、数千回のゲームを繰り返していくと
だんだんと勝てるようになっていく様子は見ていて飽きません。
youtubeに強化学習の様子がありますので、興味のある方はどうぞ。
今回は、ピンポンよりももっとシンプルなゲームで強化学習を試してみたいと思います。
誰もが一度はやった事があるであろう「〇×ゲーム(三目並べ)」を使用して、
強化学習がどんな動きで学習をしているのを見ていきます。
ピンポンを学ぶDQNではCNNを利用していますが、今回行う〇×ゲームではCNNが必要ないので、
ConvolutionではなくLinearを使用しています。
使用した環境は Ubuntu, Python, Chainer, RL_Glueです。
■ 学習の流れ
まず、今回の〇×ゲーム学習を図で表してみましょう。
学習し強くなっていく「エージェント」と、ゲームを取りまとめる「環境」に分かれています。
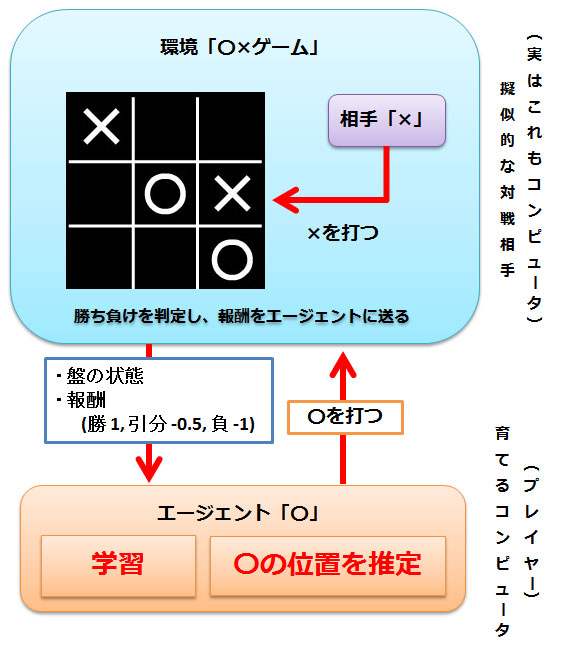
ゲームの流れを次のように定義します。
強化学習を行うために、コンピュータに教える前提条件です。
-
学習するプレイヤーは先行で〇を使います。
-
プレイヤー(育てるコンピュータ)の相手は本来ゲーム本体なのですが、ここでは次のような相手(×)を、これもコンピュータで簡単に作成しました。
・50%の確率で、ランダムに×を打つ。
・50%の確率で、以下の行動を行う。
- 一例に×が2つ並んでいて、残る一つが空白の場合、そこに×を打つ。
- 一例に〇が2つ並んでいて、残る一つが空白の場合、そこに×を打つ。
- 上2つに当てはまらない場合は、ランダムに×を打つ。 -
勝ったら1、引き分けで-0.5、負けたら-1、勝負続行で0 を報酬としてプレイヤーに渡します。
プレイヤーは、なるべく報酬が高くなるような学習をすすめ、「〇」を置いていくようになります。
学習の要点は、状態1 → プレイヤーが打つ → 相手が打つ → 状態2 → … 決着という流れの中で、「現在がどんな状態であるから、どこに打てば良い報酬が取得できるか」を学んでいくことにあります。 -
盤面を数字で表して、以下のように考えます。

例えば、この状況の時に〇が7に打つと以下のようにゲームが進んでいきます。
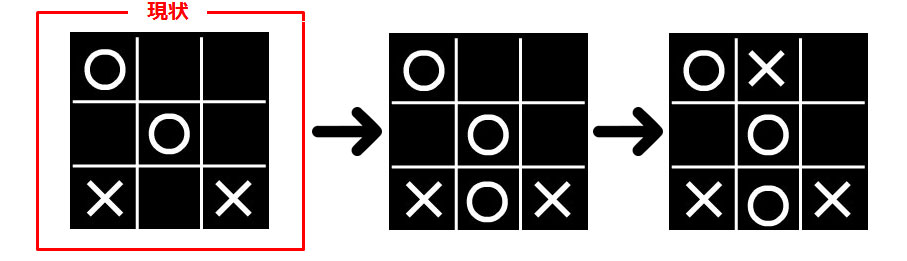
まだ勝負が続行しています。〇の7では勝負がつきませんでした。(reward = 0)
仮に、〇が7ではなく1に打った場合を見てみましょう。
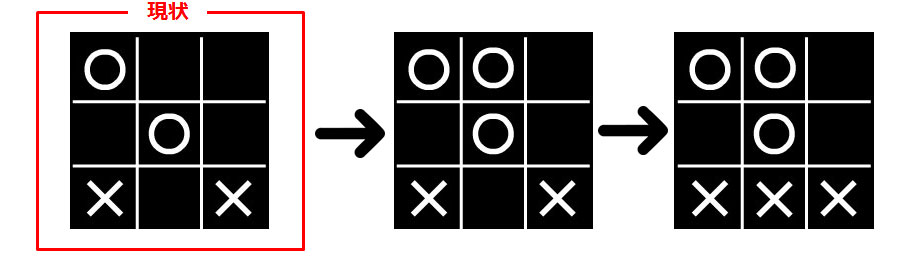
〇の負けで勝負が終わりました。(reward = -1)
この一連の流れによって、〇が 1 に打ってしまうと報酬が -1 つまり良い行動ではないという事が学習できます。
上記のように勝負がつくタイミングでの行動は学習をしやすいですが、
実際に重要なのは勝負がつくタイミングよりも前の行動であることが多いのです。
一手目に4を選択するか7を選択するかで、勝率に大きな差が出る事は容易に想定できると思います。
最後の一手だけでなく、途中の行動も学習させることにより、学習の精度をより高める事ができます。
■ 学習結果
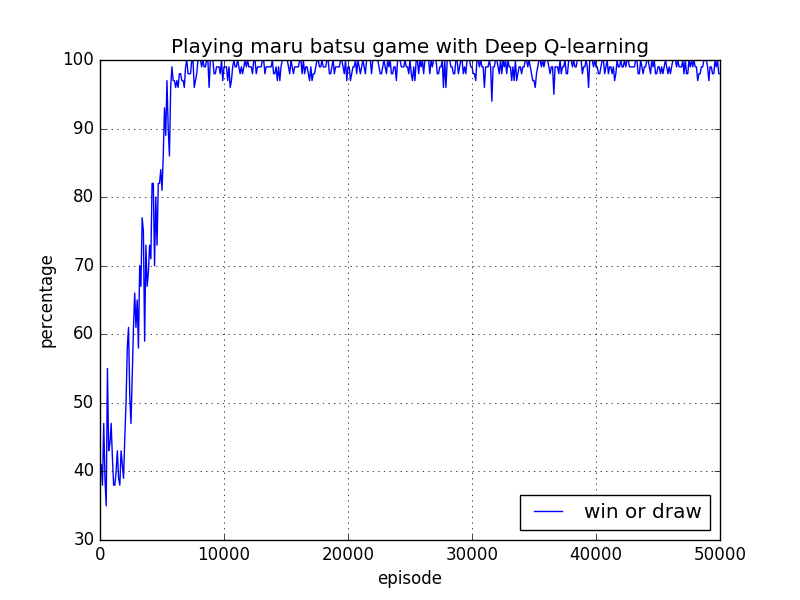
始めたばかりでは 勝ち・引き分けの確率は全体の40%でしたが、ゲームを繰り返していくと確率はどんどん上がっていきます。
6,000回繰り返した場合には勝ち・引き分けが98%、負けが2%程度となり、ほぼ負けない状態になっていました。
施行回数に対する(勝利、引き分け)の割合を示す図は以下の通りです。
■ まとめ
行動の指針を定義するだけで、勝手に上達をしていく強化学習は今色々な分野で注目を浴びています。
強化学習が活躍できそうな分野例
- 自動車の自動運転
- 工場での在庫管理・生産ライン最適化
- 高層ビルや大型店舗でのエレベータ群制御
- バックギャモンやチェス、囲碁などのゲーム
また、宇宙や海底など,通信が物理的に困難な場合や,
通信ネットワークの制御のように現象の変遷が人間にとって速すぎる場合など
自律的な適応能力が求められる場面でも活躍が期待されています。
上記以外のどんな分野においても、
人間の技術者では見つけられなかった意外な答を発見できる可能性がありますので
様々な分野で強化学習が活用される可能性があるのではないでしょうか。
強化学習を行ったコンピュータが、新たな強化学習を行うコンピュータを作成するという
時代が近くまで来ているのかもしれません。
SFであればその後コンピュータの反乱が待ち構えているところですが、これからどのような世界になるのか楽しみです。
~関連ブログ~
「強化学習でボールを自由に動かす ~ネズミを追いかけるボール Part 1~ (深層学習 Deep Reinforcement Learning )」