こんにちは。
情報をSNSなどから取得して解析をしようとすると、どうしてもジャンルで分類をする必要が出てきます。
yahooやgooのTOPページにはたくさんのニュース記事が社会・経済・生活・・・と分類されていますよね。
10件や20件であれば、手作業で分類しても良いかもしれません。ですが、数千数万となると手作業で行うには限界があります。
そんな問題を解決するために、ナイーブベイズを利用してジャンル分類を行い、どの程度マッチするものなのかについて書きたいと思います。
●ベイズ統計「見えないものをさぐる ―それがベイズ」を出版しました。詳しくはこちら
ナイーブベイズについて
ナイーブベイズ(naive bayes) は、迷惑メールを分類するためのフィルターとして使われているようです。
基本的にベイズ確率を使用します。
ベイズ(bayes)基本式
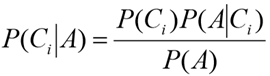
分母P(A)は分類を行う時は一定なので、
![]()
と考えられます。
Ciがジャンル、Aがテキストに含まれる1つ1つの単語にあたります。
単語AがジャンルCiに含まれる確率を、右辺の式で計算します。
ナイーブと呼ばれる所以は、そもそも単語というものは独立ではないのに、計算上独立のように扱ってしまうことから、「ナイーブ」と呼ばれているそうです。
確かに、「お菓子」、「泳ぐ」、「食べる」という単語を考えてみると、やはり何か関連がありそうですね。
「お菓子を食べる」とは言いますが、「お菓子が泳ぐ」というのはあまり聞きません。
大量のデータである場合、一台のマシンでは処理が追いつかない可能性もありますので、ここではHadoopを利用した分散処理を考えていきます。
使用するHadoopクラスタは1マスター、4スレーブの5台構成。
各マシンともに低スペック (2Core, メモリ1GB)マシンを使用しています。
MapReduceとSparkの性能も一緒に比較してみます。
〇事前準備
クラス
[IT, スポーツ, 経済] の三種類
学習用データ
各クラスに対して20ずつニュース記事を用意。
分類したい文章
ITを1つ、スポーツを3つ、経済を5つの計9つ用意
〇分類器作成
1. 単語で分解し、「は」「で」「を」などの意味をなさない単語を削除します。
サンプルでは目視・手作業にて分解を行いましたが、文章量が多くなってくると手作業での分解には限界がきます。
そのため、ここではMecabを利用して記事データを分解させる事にします。
例) mecab -b 81920 -O wakati ./init/eco/1.txt -o ./wakati/eco/1.txt
※Mecabのインストール手順につきましては、こちらを参考にしてください。
意味をなさない単語の削除も目視では厳しいので、以下のようなプログラムを作成し実行します。
String returnLine = new String();
for(String string : line.split(" ")){
if(!string.equals("あの"){
if(returnLine.length() > 0){
returnLine += " ";
}
returnLine += string;
}
}
return returnLine;
2. 各クラスの選択確率を計算します。
3. スコアを計算し、分類器を作成します。
〇分類実行
1. ターゲットとなる文章を分解し、意味をなさない文字を削除します。
2. クラス毎にスコアを計算します。
3. クラス毎にスコアをかけます。
4. スコアに選択確率をかけます。
5. スコアを比較して、数が大きいクラスに分類します。等しい場合は選択確率の大きいクラスに分類。
〇分類結果
MapReduce、Sparkともに今回用意した9つのニュース記事は100%正しい分類が行えました。
同じ日のニュースを学習データ、分類対象データとしたためだと思いますが、本来はもう少し誤分類も起きてしまうようです。
学習データと分類対象データが半年程度離れたケースについては、また後日書きたいと思います。
なお、分類器の作成・分類実行にかかった時間は以下の通りです。
| MapReduce | Spark | |
| 分類器作成 | 129秒 | 13秒 |
| 分類実行 | 25秒 | 10秒 |
| Total | 154秒 | 23秒 |
約7倍程度の差が見られました。
MapReduceでは厳しいですが、Sparkを利用すればリアルタイムでの記事追加も行えると考えられます。